Before:字符串是琴弦,想弹琴了🎸🎹🪕 Data Structure 8 字符串 字符串的定义 字符串是由若干个字符按照一定顺序组合而成,如果把单个字符看作一个元素,则可把字符串看成是一个字符类型的线性表。但区别在于,线性表中的个体大多相互独立,强调的是对表中某个元素的操作,而字符串更强调的是整体的操作,是对多个字符串的同时操作。关于字符串的基本操作有以下几种:
字符串的顺序实现 字符串本质上是一个线性表,因而可以采用顺序存储。我们要做的是创建一个字符类型的数组。我们常说C风格字符串和C++字符串,那么C语言和C++在字符串这一数据结构的处理上有何区别呢?
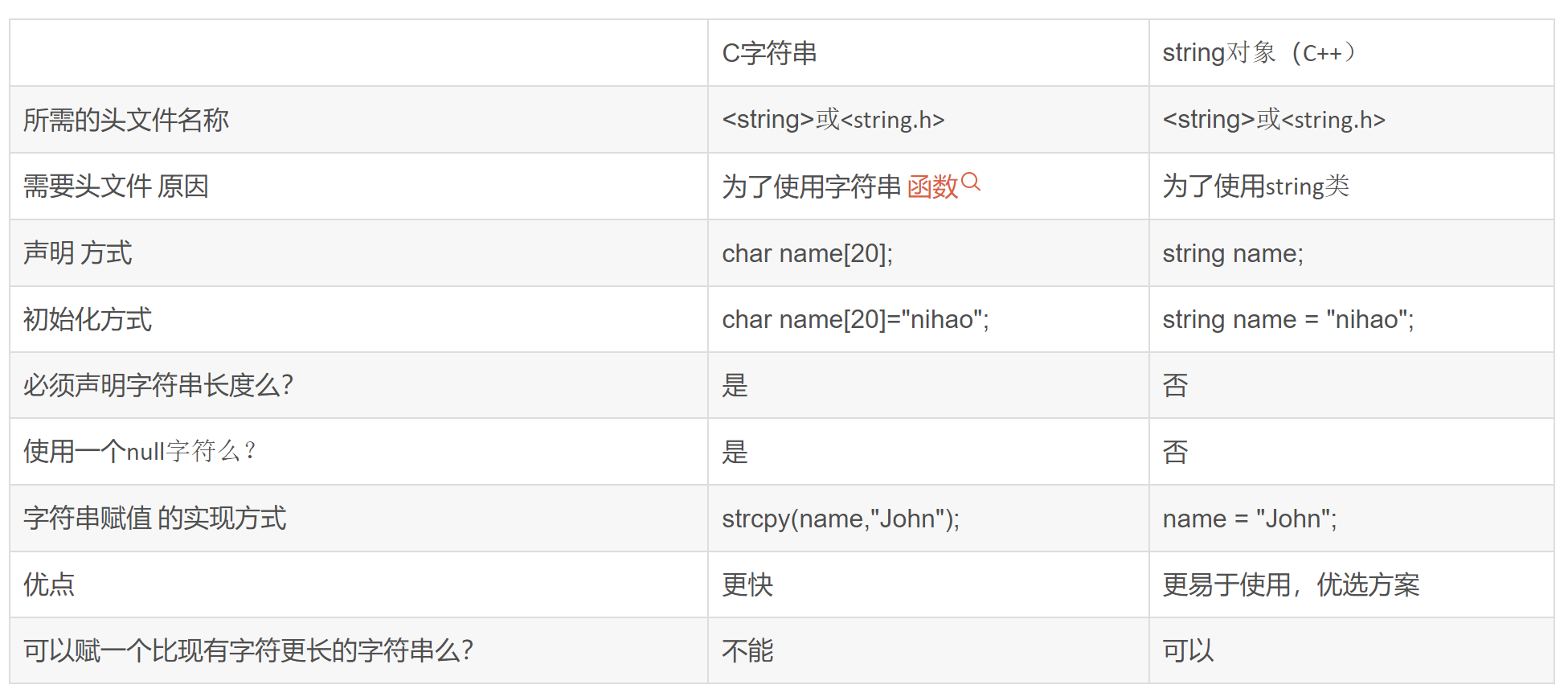
而更为底层的区别在于,C语言的字符串是采用静态的顺序存储,使用一个以null(‘\0’)字符结尾的字符数组来保存字符串,而C++中则把字符串封装成了一种数据类型string,采用动态的顺序存储,并用运算符重载实现了赋值、连接、比较等操作,使字符串类型的变量能与整型、实型等内置类型的变量一样用运算符操作。
那么顺序串的存储实现采用一个动态的字符数组(一个动态数组自然需要一个指向数组首地址的指针和数组的大小两个量),但由于C++字符串必须以’\0’结尾,故不管该字符数组后面还有多少元素,一旦遇到’\0’,即终止,故字符串类的动态字符数组不需要记录数组的大小。
字符串类的顺序实现 在上代码前,让我们先明晰一下,字符串类的实现要点:
1.构造函数:接受一个字符串常量作为参数。构造函数会动态分配一个数组来存储这个字符串。回顾《程序设计思想与方法》 ,存在动态内存分配时,简单的浅拷贝(按位复制)会导致多个对象共享同一块内存。这可能导致析构时多次释放同一内存(double free),引发未定义行为。)回顾《程序设计思想与方法》 ,运算符重载通常定义为友元函数,出于对称性的考虑,即如果其中一个操作数不是类的对象,重载为成员函数可能会导致不对称性;也出于自然语法中输入输出运算符的左操作数通常是流对象,而不是自定义类的对象。)
下面给出字符串类的定义:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 class seqString {friend seqString operator +(const seqString &s1,const seqString &s2);friend bool operator ==(const seqString &s1,const seqString &s2);friend bool operator !=(const seqString &s1,const seqString &s2);friend bool operator >(const seqString &s1,const seqString &s2);friend bool operator >=(const seqString &s1,const seqString &s2);friend bool operator <(const seqString &s1,const seqString &s2);friend bool operator <=(const seqString &s1,const seqString &s2);friend ostream &operator <<(ofstream &os,const seqString &s);char *data;int len;public :seqString (const char *s = "" );seqString (const seqString &other);seqString ();int length () const operator =(const seqString&other);seqString subStr (int start,int num) ;void insert (int start,const seqString &s) void remove (int start,int num)
** 有趣的是,这里字符串类居然没有使用类模板?!不会是因为elemType都是char吧🤣🤣🤣
接下来就是字符串类的具体实现了,话不多说,上代码!
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 seqString::seqString(const char*s){for (i = 0 ;;i++){if (s[i] == '\0' ){break ;data = new char[len + 1 ];for (i = 0 ;i <= len;i ++){data [i] = s[i];const seqString &other){data = new char[other.len + 1 ];for (int i = 0 ; i <= other.len;i ++){data [i] = other.data [i];data ;const {return len;operator ==(const seqString&other){if (this == &other){return *this ;data ;data = new char[len + 1 ];for (int i = 0 ;i <= len;i ++){data [i] = other.data [i];return *this ;if (start < 0 || start >= len){return "" ;if (start + num > len){else {data ;data = new char[s.len + 1 ];for (int i = 0 ; i < s.len;i ++){data [i] = data [start + i];data [s.len] = '\0' ;return s;const seqString &s){data ;if (start > len || start < 0 ){return ;data = new char[len + 1 ];for (int i = 0 ;i < start; i ++){data [i] = tmp[i];for (int i = start; i < start + s.len;i ++){data [i] = s.data [i - start];for (int i = start + s.len; i <= len; i ++){data [i] = tmp[i - s.len];if (start < 0 || start >= len){return ;if (start + num >= len){data [start] = '\0' ;return ;for (int i = start + num; i < len; i ++){data [i - num] =data [i];data [len] = '\0' ;operator +(const seqString &s1,const seqString &s2){data ;data = new char[tmp.len + 1 ];for (int i = 0 ; i < s1.len; i ++){data [i] = s1.data [i];for (int i = 0 ; i < s2.len; i ++){data [s1.len + i] = s2.data [i];data [tmp.len] = '\0' ;return tmp;operator ==(const seqString &s1,const seqString &s2){if (s1.len != s2.len){return false ;for (int i = 0 ; i <= s1.len; i ++){if (s1.data [i] != s2.data [i]){return false ;return true ;operator !=(const seqString &s1,const seqString &s2){if (s1 == s2){return false ;return true ;operator >(const seqString &s1,const seqString &s2){for (int i = 0 ; i < s1.len; i ++){if (s1.data [i] > s2.data [i]){return true ;else if (s1.data [i] < s2.data [i]){return false ;return false ;operator >=(const seqString &s1,const seqString &s2){if (s1 > s2){return true ;if (s1 == s2){return true ;return false ;operator <(const seqString &s1,const seqString &s2){if (s1 >= s2){return false ;return true ;operator <=(const seqString &s1,const seqString &s2){if (s1 > s2){return false ;return true ;operator <<(ofstream &os,const seqString &s){for (int i = 0 ; i < s.len; i ++){data [i];return os;
字符串类的链接实现 正常的链表理应当在一个结点中存储一个字符,这种存储方式使insert和remove操作容易实现,但太浪费空间。在每个结点中,数据只占一个字节,而指针却要占多个字节。为了提高空间利用率,可使每个结点存放多个字符,称为块状链表 😅😅😅😅😅流汗黄豆贴满了,应该能看出JaneZ对块状链表的无语了吧,一个差点要了我命的数据结构,《重生之JaneZ要斩了块状链表》,即将上演。
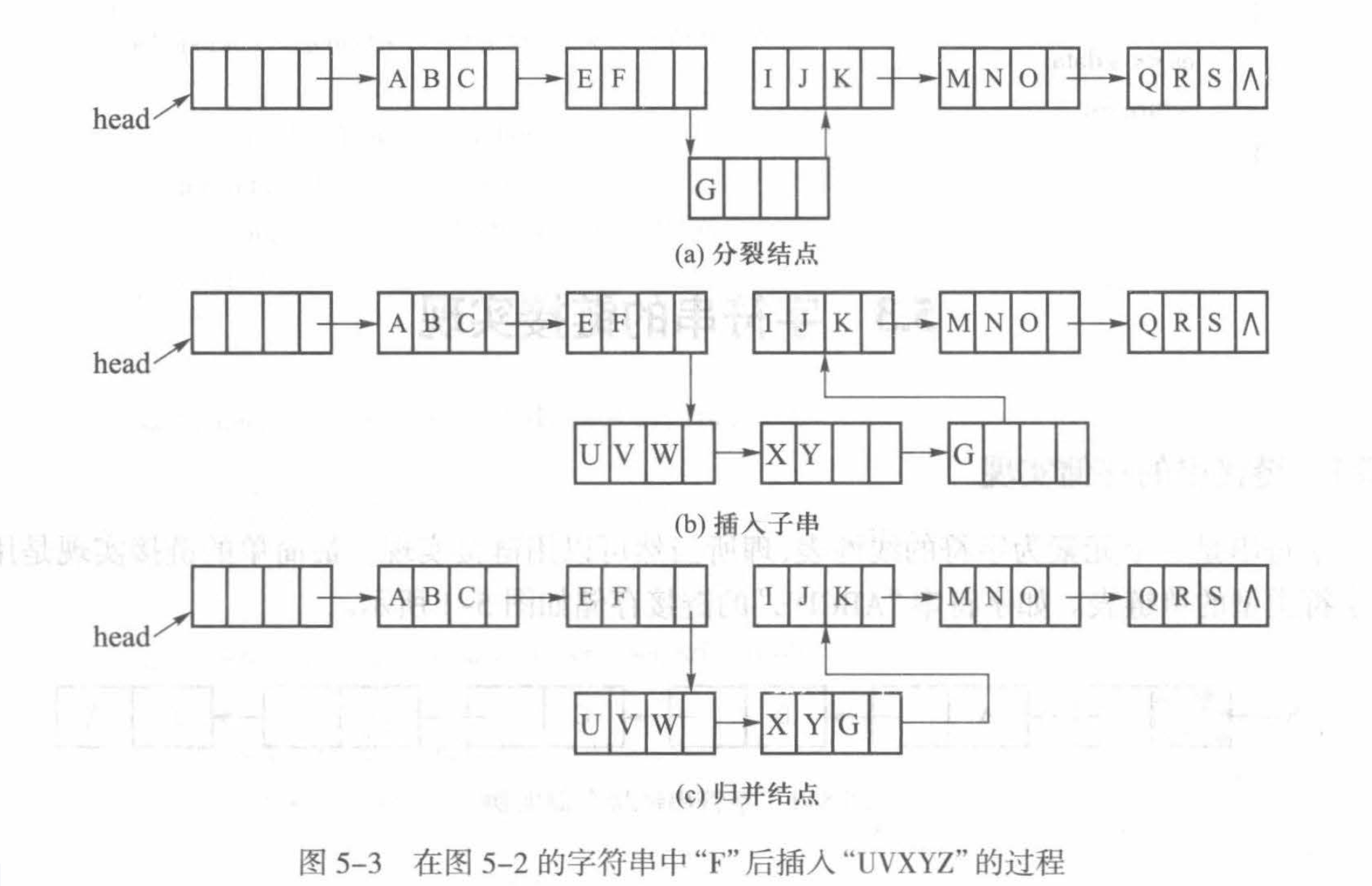
下图是一张块状链表的示意图:
如在上图的字符串中删除”C”只需在第一个结点中删除”C”,其他结点保持不变。如要删除”EFGI”只需删除第2个结点,并在原第3个结点中删除”I”。当需要在”F”后插入字符串”UVXYZ”时,先形成两个新的结点”UVX”和”YZ”,然后将结点”EFG”分裂成两个结点”EF”和”G”,将两个新结点插入它们之间。为了保证块状链表不退化成单个字符的链表,检查新插入的最后一个结点和后面一个结点能否合并成一个结点。
一些实现要点:链接串类的存储采用带头结点的块状链表。由于采用链接存储,在链接串类中定义了一个私有的内嵌类node,即链表中的结点类。每个结点由3部分组成:结点中的有效字符数、保存字符串的字符数组以及一个指向后继结点的指针。链接串类有 3 个数据成员:指向头结点的指针、字符串的长度以及每个结点的容量。
下面给出代码实现:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 class linkString {friend linkString operator +(const linkString &s1,const linkString &s2);friend bool operator ==(const linkString &s1,const linkString &s2);friend bool operator !=(const linkString &s1,const linkString &s2);friend bool operator >(const linkString &s1,const linkString &s2);friend bool operator >=(const linkString &s1,const linkString &s2);friend bool operator <(const linkString &s1,const linkString &s2);friend bool operator <=(const linkString &s1,const linkString &s2);friend ostream &operator <<(ofstream &os,const linkString &s);struct Node {int size;char *data;Node (int s = 1 ,Node *n = nullptr ){new char [s];int len;int nodeSize;void clear () void findPos (int start,int &pos,Node *&p) const void split (Node *p,int pos) void merge (Node *p) public :linkString (const char *s = "" );linkString (const linkString &other);linkString ();int length () const operator =(const linkString&other);linkString subStr (int start,int num) ;void insert (int start,const linkString &s) void remove (int start,int num)
关于块状链表的性能,研究表明(事实上好像未必),块状链表的结点容最与结点个数相同时算法的效率是最高的。所以将结点数量设为 $\sqrt{len}$
具体实现:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 linkString::linkString(const char *s = "" ){for (i = 0 ;;i++){if (s[i] == "\0" ){sqrt (len);while (*s){p = p ->1 );for ( ; p ->size < nodeSize && *s; p ->p ->data [p->1 );ode *otherp = other.head ->while (otherp){p = p ->1 );for (;p ->size < other.nodeSize && otherp ->data [p ->size ];p ->p ->data [p ->size ] = otherp ->data [p ->otherp = otherp ->ode *p = head ->while (p){p = p ->if (other == this){ode *otherp = other.head ->while (otherp){p = p ->1 );for (;p->size < other.nodeSize && otherp->data [p->size ];p ->size ++, otherp->data ++){p ->data [p->size ] = otherp->data [p->otherp = otherp ->if (start < 0 || start >= len){p = head ->0 ;while (p){if (start - count > p.size){p = p ->else {if (start < 0 || start >= len){ode *tmpp = tmp ->if (start + num > len){sqrt (num);for (int i = 0 ; i < num;){tmpp = tmpp ->for (;tmpp ->size < tmp.nodeSize && i < tmp.len;i ++,tmpp->if (pos == p ->p = p ->0 ;tmpp ->data [tmpp ->size ] = p ->data [pos ++];p ->next = new node(nodeSize,p ->for (int i = pos; i < p ->p ->next ->data [i - pos] = p ->p ->next ->size = p ->p ->de *tmp = p ->if (tmp ->size + p ->for (int i = p ->size ; i < tmp->size + p ->p ->data [i] = tmp ->data [i - p ->p ->size = tmp ->size + p ->p ->next = tmp ->
⭐下面是比较重要的insert和remove的实现:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 void linkString::insert(int start,const linkString &s){if (start < 0 ||start >= len){ode *stmp = s.head ->tmp = p ->while (stmp){for (pos = 0;pos < stmp ->if (pos == p ->p = p ->p ->data [p ->size ] = stmp ->data [pos];p ->stmp = stmp ->p ->if (start < 0 ||start >= len){if (start + num > len){else {while (true ){ode *tmp = p ->if (num - tmp->0 ){num -= tmp ->p ->next = tmp ->else {p ->next = tmp ->
重载运算符部分与顺序实现类似,较容易,就不写了(bushi)。又一遍块状链表真是把人快搞死了😅,真难写啊呜呜呜…字符串相关算法(kmp,字符串哈希等)上学期上机课有过介绍,就不会再出现了(偷懒😋)
Reference CSDN:https://blog.csdn.net/yf210yf/article/details/8777131 https://blog.csdn.net/tuolaji8/article/details/51362698